

Gastbeitrag: Meine ersten ITSM Process Mining Erfahrungen
Process Mining ist ein Verfahren des Prozessmanagements, das es ermöglicht, Businessprozesse auf Basis digitaler Spuren in IT-Systemen, in unserm Fall in ITSM-Systemen, daher ITSM Process Mining, zu rekonstruieren und zu analysieren.
Die in den Systemen gespeicherten einzelnen Schritte des Prozesses werden zusammengefügt und der Prozess in seiner Gesamtheit visualisiert.
Process Mining ermöglicht es, das in Daten enthaltenes, implizites und sonst verborgenes Prozesswissen zu modellieren und somit greifbar und transportierbar zu machen. Eine allgemeine Erläuterung und Beschreibung finden Sie auf Wikipedia. Hier gibt es einen sehr guten Artikel von Dr. Anne Rozinat „Process Mining: Von Stichproben zu umfassender Analyse“, der gut erklärt wie die Sache funktioniert.
Warum Process Mining überhaupt eingesetzt wird
Die Technik Process Mining wird oft verwendet, wenn durch andere Herangehensweisen keine formale Beschreibung der Prozesse möglich ist, oder wenn die Qualität existierender Prozessaufzeichnungen fragwürdig ist.
Um es verständlicher zu machen möchte ich hier ein einfaches ITSM-Beispiel anführen:
Wenn man bspw. wissen will, wie der Incident Prozess in einem Unternehmen wirklich abläuft, dann muss man aus dem Tool, das man dafür einsetzt, folgende Informationen auslesen: Welcher Prozessschritt (bspw. erkennbar am Status), wird für welchen Fall (Incident Nr., UID) in welcher Reihenfolge (Timestamp) durchlaufen.
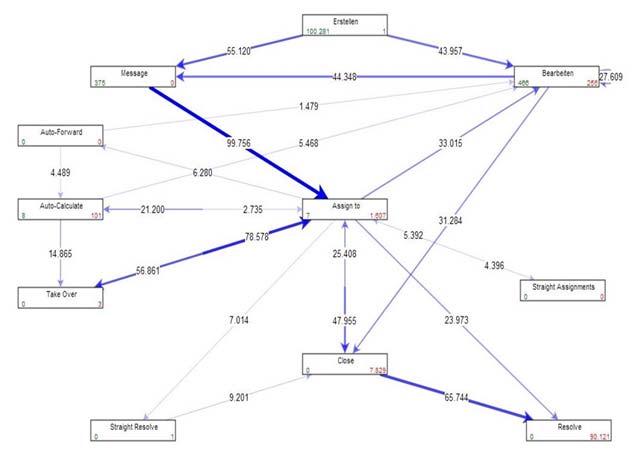
Ergebnis der Auswertung des tatsächlichen Prozesses in einem Tickettool.
Dieser Graph wird von dem unterstützenden Process Mining Werkzeug generiert. Der wesentliche Unterschied zur klassischen Prozessmodellierung ist also jener, dass der Prozess nicht auf Basis von theoretischen Annahmen, sondern vielmehr auf Basis von real gelebten Abläufen automatisch dargestellt werden kann. Über die Zahlen auf den Kanten der Graphen lässt sich ablesen wie häufig der reale Ablauf diesen Weg geht. Hier wird die relative Häufigkeit zusätzlich durch die Strichstärke noch verdeutlicht.
Je mehr Attribute erfasst werden, umso sinnvoller wird die Auswertung
Bereits mit diesen drei einfachen Feldern lässt sich schon ein sehr informativer Graph aufbauen. Wirklich interessant wird die Methode jedoch erst, wenn man weitere Informationen aus dem Quellsystem zum Filtern der Ansichten einsetzt. Beim gezeigten Graphen macht es bspw. Sinn nach Bearbeitergruppe, oder Ticketkategorie oder auch nach Standort der Einmelder zu filtern.Auf diese Weise lassen sich sinnvolle Auswertungen erstellen.
Typische Kriterien:
- Tickettyp
- Kategorie
- Priorität
- Auswirkung
- Dringlichkeit
- Eingangsquelle
Bewährte Mengenauswertungen:
- Volumen eingehender Tickets
- Auswertung der meldenden Abteilungen
- Auswertung der Eingangskanäle
- Volumen der Ticketeröffnung pro Team (bspw. Vermeidung Hey Joe)
- Entwicklung der Ticketvolumina nach verschiedenen Klassifizierungen (z.B. Ticket Kategorisierung, Ticket Typ)
- Effizienz und Häufigkeit der Nutzung von Kategorisierung, Priorisierung etc.
ITSM Performance Indikatoren:
- Reaktionszeiten (bspw. für verschiedene Meldemedien zu Servicezeiten)
- Sofortlösungsquoten
- Lösungsquoten
- Lösungszeiten (insgesamt bzw. während der Servicezeiten)
- Liegezeiten der Tickets
- Bearbeitungszeiten (bspw. verschiedener Teams)
- (Durchschnittliche) Anzahl Bearbeiter pro Ticket
- (Durchschnittliche) Anzahl Teams beteiligt pro Ticket
- Auswertung der Ticketqualität (sind alle notwendigen Felder ausgefüllt?)
Was wir mittels Process Mining schon finden und daher verbessern konnten
Hey Joe Ticketeröffnung (Tickets werden im 2nd & 3rd Level eröffnet)
Häufig ist es nicht gewünscht, dass die Tickets am Single Point of Contact (SPoC) vorbeigespielt werden. Vor allem nach Einführungsprojekten zeigt sich, dass viele Benutzer oft das manchmal jahrzehntelang gelebte Verhalten einfach beim Spezialisten anzurufen nicht so gerne aufgeben möchten. Da wird dann direkt beim SAP Betreuer angerufen, weil ein neuer Mitarbeiter eine Berechtigung braucht. Nicht nur, dass diese Anrufe die Mitarbeiter von Ihrer eigentlichen Tätigkeit abhalten, sondern meist sind die Spezialisten im 2nd oder 3rd Level einfach viel zu teuer um solche einfachen Dinge auszuführen.
Wir machen daher regelmäßig die Kontrolle, ob irgendwo wieder Inseln entstehen, wo dieses Verhalten wieder einreißt. Häufig ist das nach der unsauberen Übergabe von Projekten an den Betrieb der Fall. Dann heißt es Knowledge und Kompetenz an den First Level zu bringen, sodaß dieser besser und schneller helfen kann. Dann rufen die User auch gerne beim SPoC an.
Langläufer Tickets (Tickets, die [sehr] lange nicht gelöst werden)
Eine gute Prozess Mining Software Lösung unterstützt das einfache Filtern nach Anomalien. Dies kann man sich gut zu Nutze machen, wenn man wissen will, warum manche Dinge praktisch nie gelöst werden. Erst durch die Visualisierung kann man erkennen, was da manches Mal schief läuft. Ich hatte schon Kunden, wo die Incident Manager verzweifelt waren, da sie tagelang recherchieren mussten, um dann ihren Vorgesetzten zu berichten, warum dieses eine Ticket wiedermal liegen geblieben ist. Haute sind sie proaktiv unterwegs, und fangen mittels automatischer Auswertungen, die ein „normales“ Tickettool nur schwer abbilden kann, viele Probleme schon im Entstehen ab. Und gleichzeitig haben sie ein starkes Mittel zur Analyse, wenn einmal was schief geht.
Multiple Hops (Tickets mit [sehr] vielen Weiterleitungen)
Häufig werden Vielfachweiterleitungen schon als KPI vom Ticketsystem geliefert, aber mittels Process Mining kann man bspw. nach mehreren Kriterien filtern, und sieht dann genau wie der Hase (bzw. das Ticket) läuft.
Mangelnder Shift Left (zu häufige Weitergabe einfacher Themen an nachgelagerte Bereiche)
Service Excellence und Lean Services erreicht man nur durch Vermeidung von Verschwendung (Waste). Und die Weitergabe von Tickets an nachgelagerte Gruppen, entspricht gleich 7 von 8 Waste-Kriterien:
- Delay, denn die Kunden (user) müssen unnötig lange warten
- Duplication, denn häufig werden Informationen dabei mehrfach erfasst
- Unnecessary Movement, denn wozu trägt die Weitergabe wirklich bei, außer zur Verzögerung
- Unclear communication, weil häufig die User verunsichert werden, und auch sehr häufig der Nächste im Prozess nochmals nachfragen muss
- An opportunity lost to retain or win customers, denn wenn man zuerst einen Single Point of Contact einführt, und dieser dann nicht helfen kann, dann ist das einfach unfreundlich
- Errors in the service transaction, zum Gesamtservice gehört auch der Support, und der sollte Störungen wie Eskalationen vermeiden
- Service quality errors, denn wenn sich keiner auskennt, oder zuständig fühlt, dann kann die Qualität nicht passen.
Mittels Process Mining gelingt es immer wieder solche Probleme zu entdecken, einzuschränken, um etwas dagegen machen zu können. Gleichzeitig können unnötige Ping-Pong-Tickets zwischen verschiedenen Teams aufgedeckt werden.
Selbstweiterleitungen innerhalb eines Teams (an andere Bearbeiter)
Was wir immer schon wussten, können wir nun endlich konkret visualisieren …
Prozessineffizienz und Bottlenecks (z.B. bestimmte Teams weisen sehr lange Reaktions- und Bearbeitungszeiten auf)
Wie bereits auf dem einfachen Beispielbild ersichtlich, ist es auf den ersten Blick möglich zu erkennen, wo die Zeit liegen bleibt. Das hilft immens, von theoretischen KPI-Zahlenkolonnen zu realen Aussagen zu kommen.
Bereits bewährt und guter Ausblick
Bei den ersten Versuchen, die ich mit meinen Klienten gemacht habe, hat Process Mining sofort einen Platz im Herzen der Verantwortlichen für Qualität, Performance, Conformance, kontinuierlichen Verbesserung, Service Excellence, etc. gefunden. Ein Prozess-Verantwortlicher sagte mir: „So viele Quick Wins hatten wir schon lange nicht mehr!“
Und ich denke, da gibt es noch viele Möglichkeiten, an die ich noch gar nicht gedacht habe …
Haben Sie bereits Erfahrungen? Kommentare sind willkommen!
